2016/07/22
2020/05/04
ファイルからのデータ読み込みとアクセス【第2回】
【第1回】ベクトル・行列の作成と四則演算・要素の参照
【第2回】データ読み込みとデータの取り出し方 ←今ここ!!
【第2.5回】Rで解析する上で知っておきたい便利なコマンド集
【第3回】Rで線形モデルによる回帰分析
【第4回】Rでの自作関数の作り方・使い方
【第5回】グラフのプロットと画像保存の方法(回帰直線)【終】
※R言語入門のトップページはこちら
今回は実データの扱いに入ります。RではテキストファイルやExcelファイル(多くの場合csv形式のファイル)を変数に読み込んで解析を行うことが多いです。この時、データはデータフレーム型という形式で読み込みが行われます。
今回は、「どのようにしてファイルの中身を変数データフレーム型で読み込んでR上で操作するのか」について解説していきます。
sample-data.csv←今回使う解析用のファイル(csv形式)です。皆さんも、是非ダウンロードしてR上で動かしてみましょう!こんな感じのデータになってます。
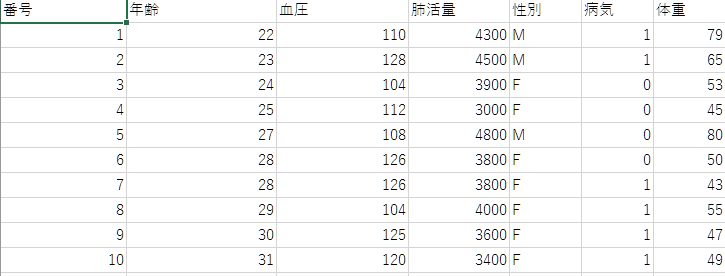
データの読み込み方とデータのアクセス(参照)方法
データ読み込み方
Rでcsv形式のファイルをデータフレーム型で読み込む時に使う関数として”read.csv()”というものが用意されています。
データの読み込み自体は1行で済みます。
ここでのポイントは以下の3つ。
①読み込みたいデータのファイル名を””で囲む。
②headerは列名があるか無いかを指定。あるときはT(TURE)、ない時はF(FALSE)今回のデータは一行目に年齢や血圧などの列名が入っているデータを扱っているのでheader=Tで読み込みを行っています。デフォルトでheaderはTRUEであるので指定しなくても大丈夫ですが、ここでは一応指定してあります。
③row.namesは行名の指定。row.names=1だと1列目が列名になる。今回のデータは1列目は番号が書いてあるのでrow.names=1を指定して、1列目を行名として扱っています。
※注意
ファイルの読み込みは、ファイルが存在しているディレクトリに移動する必要があります。移動は、
setwd(ディレクトリへのパス)
で可能です。
例)
setwd(“/Users/username/Desktop”)
詳しくは→プログラムで作業ディレクトリを変更する方法
ここでdfの中身はこのようになっているはずです。
年齢 血圧 肺活量 性別 病気 体重
1 22 110 4300 M 1 79
2 23 128 4500 M 1 65
3 24 104 3900 F 0 53
4 25 112 3000 F 0 45
5 27 108 4800 M 0 80
6 28 126 3800 F 0 50
7 28 126 3800 F 1 43
8 29 104 4000 F 1 55
9 30 125 3600 F 1 47
10 31 120 3400 F 1 49
11 32 116 3600 M 1 64
12 32 124 3900 M 0 61
13 33 106 3100 F 0 48
14 33 134 2900 F 0 41
15 34 128 4100 M 1 70
16 36 128 3420 M 1 55
17 37 116 3800 M 1 70
18 37 132 4150 M 1 90
19 38 134 2700 F 0 39
20 39 116 4550 M 1 86
21 40 120 2900 F 1 50
22 42 130 3950 F 1 65
23 46 126 3100 M 0 58
24 49 140 3000 F 0 45
25 50 156 3400 M 1 60
26 53 124 3400 M 1 71
27 56 118 3470 M 1 62
28 58 144 2800 M 0 51
29 64 142 2500 F 1 40
30 65 144 2350 F 0 42
行列と似ていますね。行列との違いはデータフレームでは全ての行と列が必ず列名行名(ラベル)を持っているということです。そしてデータフレームでは、この列名行名による操作が可能になっています。
ここで使ったコマンド、関数を説明は重複しますが、一覧で載せておきます。
| コマンド | 使い方 |
|---|---|
| read.csv | csv形式のファイルを読み込む関数。"ファイル名が.csv"で終わっているものを読み込む。 |
| header | 一行目を列名として読み込むか否か。header=TRUEで一行目は列名扱い。 |
| row.names | データ詠み込み時に行名を設定。row.names=aでa列名を行名として扱う。空白で行名なし。 |
データのアクセス(参照)方法
データフレームの特徴は、指定すれば任意の要素へアクセス出来ることです。例えば、データの1列目だけを見たり、1行目だけを見たり、列名が”年齢”の列だけを参照したり、、、という具合にです。ではどうすればできるのか実際にプログラムを見てみましょう。
df[1,] #1行目のデータ
df$年齢 #「年齢」という名の列のデータ
このようなプログラムで指定した列や行にアクセスできます。結果は次のようになっているはずです。
[1] 22 23 24 25 27 28 28 29 30 31 32 32 33 33 34 36 37 37 38 39 40 42 46 49
[25] 50 53 56 58 64 65
> df[1,] #1行目のデータ
年齢 血圧 肺活量 性別 病気 体重
1 22 110 4300 M 1 79
> df$年齢 #「年齢」という名の列のデータ
[1] 22 23 24 25 27 28 28 29 30 31 32 32 33 33 34 36 37 37 38 39 40 42 46 49
[25] 50 53 56 58 64 65
$を使えば指定の列名のデータにもアクセスできます。「参照したい部分が何列目かは数えないと分からないけど、列名はすぐ分かる」というような時に非常に便利に使えるコマンドなのでぜひ覚えておいてください。データ参照で頻繁に使うコマンド例です。次の項でさらに詳しく触れていきます。
| コマンド | 使い方 |
|---|---|
| df$列名 | 「列名」という名の列のデータを参照 |
| df[,a] | a列目のデータを参照。 |
| df[b,] | b行目のデータを参照。 |
| df[,c(a,b)] | a列目とb列目のデータを参照 |
データの取り出し方
Rでは、データの任意の部分を参照するだけでなく、ほかの変数に代入することによって保存することもできます。大きなデータから必要なデータだけを取り出して保存したい時などに使えます。
では早速6つの例を見てみましょう。データをどのように取り出せたのでしょうか。ここでは新登場のコマンド”subset”というものを使います。
例1:男性だけを取り出す
男性だけを取り出す場合、男性は性別の列が”M”であるので、以下のようなプログラムで取り出せます。三種類ありますが、どれも同じ意味です。
M.dat <- subset(df,df[,4] == “M”)
M.dat <- df[df$性別 == “M”,]
例2:体重が60kg未満の人を取り出す。
体重が60kg未満の場合は体重の列を取り出し、それに対して<60で指定します。
weight60 <- df[df[,6]<60,]
例3:男性かつ体重が60kg未満の人を取り出す。
例1と例2の両方を満たしていないといけないので、二つの条件を書いてを&(かつ)で結びます。
M.60 <- df[df[,4]==”M” & df[,6]<60,]
例4:肺活量4000以上の人を取り出す
肺活量の列を取り出し、それに対して>=4000で4000以上の指定を行います。
例5:肺活量が3000以上、4000以下の人を取り出す。
肺活量の列に対して、3000以上と4000以下の指定を行い&(かつ)で結びます。
例6:病気の列が1であり、体重が7kg以上の人を取り出す。
病気の列に対して==1を指定し、体重の列に対して>=70を指定。二つを&(かつ)で結びます。
それぞれ、どのようなデータになったかは、ここに載せるとあまりに長くなるので載せませんが、よかったら自分で確認してみてくださいね。
今回使ったコマンドやテクニックを表で見ていきましょう。
| コマンド | 使い方 |
|---|---|
| subset(変数,条件) | 変数の条件に合うものを取り出す。subset(df,df$性別=="M")でdfという変数の性別の列が”M”であるものを取り出した。 |
| 変数[行の条件,列の条件] | 変数内の条件にあったものを取り出す。df[df$性=="M",]でdf内の行の条件で性別の列について”M”であるものだけを取り出す。列の条件は空白なので行の条件を満たす、全ての列を取り出している。 |
| "==" | 一致。a==bでaがbと等しいときTRUE(真)になる。 |
| <=,>= | それぞれ以下、以上の意味。条件を満たすときTRUEを返す。 |
| & | かつの意味。(条件式A & 条件式B)で条件式Aと条件式Bを両方満たすとき、TRUE。ベクトルを扱う場合、c言語などと違い、&&(2つ)ではなく&(1つ)なので要注意。変数を扱う場合はC言語と同様に&&(2つ)を使用。 |
まとめと復習用コピペプログラム
いかがでしたでしょうか?今回はExcelデータをRで変数にデータフレーム型読み込んで、任意の部分を参照したりする方法を学びました。次回からいよいよ統計的手法を用いたデータ処理に入ります。解析に使いたい部分のデータだけを取り出したりするときに、今回学んだことを思い出して頂ければと思います。復習用に今回使ったプログラムを全て載せておきます。
df <- read.csv(“sample-data.csv”,header=T,row.names=1)#①読み込みたいデータ名を””で囲む
#②headerは列名があるか無いか。あるときはT(TURE)、ない時はF(FALSE)
#③row.namesは行名の指定。row.names=1だと1列目が列名になる#データのアクセス
df[,1] #1列目のデータ
df[1,] #1行目のデータ
df$年齢 #「年齢」という名の列のデータ#データの取り出し方
#例1:男性だけを取り出す
M.dat <- subset(df,df$性別==”M”)
M.dat <- subset(df,df[,4]==”M”)
M.dat <- df[df$性別 ==”M”,]#例2:体重が60kg未満の人を取り出す
weight60 <- subset(df,df$体重<60)
weight60 <- df[df[,6]<60,]#例3:男性かつ体重が60kg未満の人を取り出す
M.60 <- subset(df,df$性別==”M” & df$体重<60)
M.60 <- df[df[,4]==”M” & df[,6]<60,]h<-subset(df,df$肺活量>=4000)
h
h1<-subset(df,df$肺活量>=3000 & df$肺活量<=4000)
h1
b<-subset(df,df$病気==1 & df$体重>=70)
b
【第1回】ベクトル・行列の作成と四則演算・要素の参照
【第2回】データ読み込みとデータの取り出し方 ←今ここ!!
【第2.5回】Rで解析する上で知っておきたい便利なコマンド集
【第3回】Rで線形モデルによる回帰分析
【第4回】Rでの自作関数の作り方・使い方
【第5回】グラフのプロットと画像保存の方法(回帰直線)【終】
※R言語入門のトップページはこちら







COMMENT
その他7件のコメントを表示する
-
初心者 2017.12.31 9:19 PM
ファイルを読み込むことができません。
できればもう少し詳しい解説をお願い致します。エラーメッセージ:
(file, “rt”) でエラー: コネクションを開くことができません
追加情報: 警告メッセージ:
file(file, “rt”) で:
ファイル ‘sample-data.csv’ を開くことができません: No such file or -
IMIN 2017.12.31 10:57 PM
コメントありがとうございます。
このエラーは、現在のディレクトリにファイルが存在しない場合に表示されるものです。読み込みたいファイルがあるディレクトリへの移動は済んでいますか?
ディレクトリの移動は、
setwd(ディレクトリへのパス)
で可能です。
例)
setwd(“/Users/username/Desktop”)ぜひお試しください。
-
R 2018.5.2 12:44 PM
Macでsample-data.csvを開こうとしのですが
df <- read.csv("sample-data.csv",header=T,row.names=1)
make.names(col.names, unique = TRUE) でエラー:
'ԍ’ に不正なマルチバイト文字がありますこれが出てきてしまいます。
その原因がsetwd()これをやっていなかったことなのかと思ったのですが例ではsetwd(“/Users/username/Desktop”)となっていますが()のなかに何をいれればいいのかわかりません。 -
IMIN 2018.5.8 2:23 PM
Macの場合は読み込み時オプションで、fileEncoding=”CP932″ をつけないとエラーが発生することがあります。
また、stewed()の()の中には、ファイルのあるフォルダへのパスを入れてください。例は、読み込みたいファイルがデスクトップにある場合です。パスというのは、宛先のようなものでファイルを選択してwindowsならプロパティ、macなら情報を見るで見ることができます。
そこに表示されてるものをコピーアンドペーストでsetwd()の()内に入れるとうまくいくと思います。
ただし、windowsの場合はただコピーアンドペーストするだけだと、/が逆向きになっているかもしれないので、そこを/に書き換えてください。
-
Shima 2018.6.1 5:30 PM
read.csv(“sample-data.csv”, header=T, row.names=1, fileEncoding=”CP932″)
以上のように書き換えることで私は読み込めました。
もし、解決していなければ試してみてください。 -
さっきインストールした者 2018.6.28 9:43 PM
誤字でしょうか? → df[df$性==”M”,]
-
IMIN 2018.6.29 5:13 PM
ご指摘ありがとうございます。
修正いたしました。
-
R初心者 2018.7.2 2:44 PM
いつもお世話になっております。
先日からこちらのサイトでRの勉強を始めた者ですが、一つ表記通りにならない箇所がありましたので、ご教授願います。> df[,1] #1列目のデータ
> df$年齢 #「年齢」という名の列のデータ(1列目が年齢であれば)上記は同じ意味になると解釈したのですが、前者はリストを取得するのに対し、後者はデータを取得しました。
(こちらのサイトでは、どちらもデータを取得すると読み取れました。)私が間違えているのであれば特に問題はないのですが、ご確認頂ければ幸いです。
-
R初心者 2018.7.2 6:10 PM
いつもお世話になっております。
先ほど連絡差し上げた件(df$年齢 = df[, 1])ですが、私の勘違いでした。具体的にはlistとdata.frameを勘違いしておりました。
お騒がせ致しました。 -
rue ikeya 2018.7.8 3:40 PM
fileEncoding=“CP932”をつけて読み込めたように見えましたが、
呼び出してみると、読み込めていないようです。
何が問題なのでしょうか?> df df
function (x, df1, df2, ncp, log = FALSE)
{
if (missing(ncp))
.Call(C_df, x, df1, df2, log)
else .Call(C_dnf, x, df1, df2, ncp, log)
} -
IMIN 2018.7.8 3:52 PM
コメントありがとうございます。
ダブルクオーテーションが全角になってはいませんか?確認してみてください。
Recommended
 2016年7月22日 実行するだけでR言語入門出来るプログラム
2016年7月22日 実行するだけでR言語入門出来るプログラム- 2016年7月22日 Rでのベクトル・行列の作成と四則演算・要素の参照【第1回】
- 2016年7月22日 Rでグラフをプロットして保存する【第5回】
- 2016年7月22日 R言語での自作関数の作り方・使い方【第4回】
- 2016年7月22日 R言語の便利なコマンド集【第2.5回】





初心者 2017.12.31 9:19 PM
ファイルを読み込むことができません。
できればもう少し詳しい解説をお願い致します。
エラーメッセージ:
(file, “rt”) でエラー: コネクションを開くことができません
追加情報: 警告メッセージ:
file(file, “rt”) で:
ファイル ‘sample-data.csv’ を開くことができません: No such file or
IMIN 2017.12.31 10:57 PM
コメントありがとうございます。
このエラーは、現在のディレクトリにファイルが存在しない場合に表示されるものです。
読み込みたいファイルがあるディレクトリへの移動は済んでいますか?
ディレクトリの移動は、
setwd(ディレクトリへのパス)
で可能です。
例)
setwd(“/Users/username/Desktop”)
ぜひお試しください。
R 2018.5.2 12:44 PM
Macでsample-data.csvを開こうとしのですが
df <- read.csv("sample-data.csv",header=T,row.names=1)
make.names(col.names, unique = TRUE) でエラー:
'ԍ’ に不正なマルチバイト文字があります
これが出てきてしまいます。
その原因がsetwd()これをやっていなかったことなのかと思ったのですが例ではsetwd(“/Users/username/Desktop”)となっていますが()のなかに何をいれればいいのかわかりません。
IMIN 2018.5.8 2:23 PM
Macの場合は読み込み時オプションで、fileEncoding=”CP932″ をつけないとエラーが発生することがあります。
また、stewed()の()の中には、ファイルのあるフォルダへのパスを入れてください。例は、読み込みたいファイルがデスクトップにある場合です。パスというのは、宛先のようなものでファイルを選択してwindowsならプロパティ、macなら情報を見るで見ることができます。
そこに表示されてるものをコピーアンドペーストでsetwd()の()内に入れるとうまくいくと思います。
ただし、windowsの場合はただコピーアンドペーストするだけだと、/が逆向きになっているかもしれないので、そこを/に書き換えてください。